Questions¶
Here I keep track of some questions I really wanted to answer during my studies on CUDA C.
If CUDA C manages the distribution to the threads and blocks, what are the implications of using different block and thread sizes?:
???
If the shared memory latency is
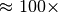 lower than uncached
global memory latency, how to make the access to the array more cache
friendly?:
lower than uncached
global memory latency, how to make the access to the array more cache
friendly?:???